
Harmony AI: How we resolve 90% of merge conflicts and accelerate Android software updates
A preview of Harmony - our LLM-powered system that automatically resolves 88% of merge conflicts, cutting integration time, reducing the risk of bugs, and accelerating Android software updates.
The Merge Pain Of Every Software Update
Here is an early preview of Project Harmony - our AI system for automatic merge conflict resolution, that solves one of the biggest pain points in keeping device software up to date and the hidden reason many devices rarely receive software updates.
Device software isn’t static. Upstream Android and Linux integrate security fixes daily and new features regularly. Device makers take these foundations and extensively modify them by adding their own hardware and custom features. But with every new upstream release, these device-specific changes need to be re-applied and rebased, in order to keep devices updated - a repetitive and error-prone process that results in merge conflicts.
At the scale of a device codebase, spanning hundreds of millions of lines of code, churning and growing by 15–20% each year, the volume and complexity of merge conflicts is enormous. Each conflict resolution carries the risk of introducing new bugs, on devices that have already shipped and are no longer the main focus of internal development.
Today, device makers face two choices: dedicate entire engineering teams to resolving conflicts or limit software updates - to avoid the costs, defect risk and resource drain. Upcoming global cyber regulation makes the second option no longer a viable choice.
The first option isn’t great either. Aside from the labour cost, resolving merge conflicts is repetitive work that offers little reward. Imagine being dropped into the middle of two developers’ conflicting changes, with little context for what each was trying to achieve.
Harmony aims to solve this by automatically resolving, validating, and explaining merge conflicts - freeing developers to focus on building great software. The challenge is doing this at a fraction of the cost and without introducing new or hard-to-find bugs, which large language models (LLMs) can sometimes introduce.
Challenge accepted - and here’s how we do it.

Why Do We Use Smaller, Specialised Models?
LLMs exhibit strong generalisation and emerging reasoning capabilities, making them powerful tools for broad, open-ended tasks. However, for well-defined problems and specialised domains, small language models (SLMs) offer a more practical and efficient alternative.
Not only can SLMs be 10-30x cheaper to run and deploy compared to LLMs, but recent studies also show that specialised SLMs (e.g., Phi-3.5-mini (3.8B), DeepSeek-Coder (6.7B)) can achieve comparable performance to models exceeding 70B parameters on coding benchmarks like HumanEval and MBPP.
In our work on automating merge conflict resolution, we reached similar conclusions and determined that: to fix merge conflicts for device codebases, we need to optimise accuracy, explainability, and reduce new or hard-to-find bugs (pick all 3).
To achieve this we developed a family of domain-specialised SLMs, which we call Harmony. These models are based on smaller models such as Llama-3.1-8B and Qwen3-4B, and fine-tuned on a high-quality dataset of code-merging examples derived from the Android Open Source Project (AOSP).
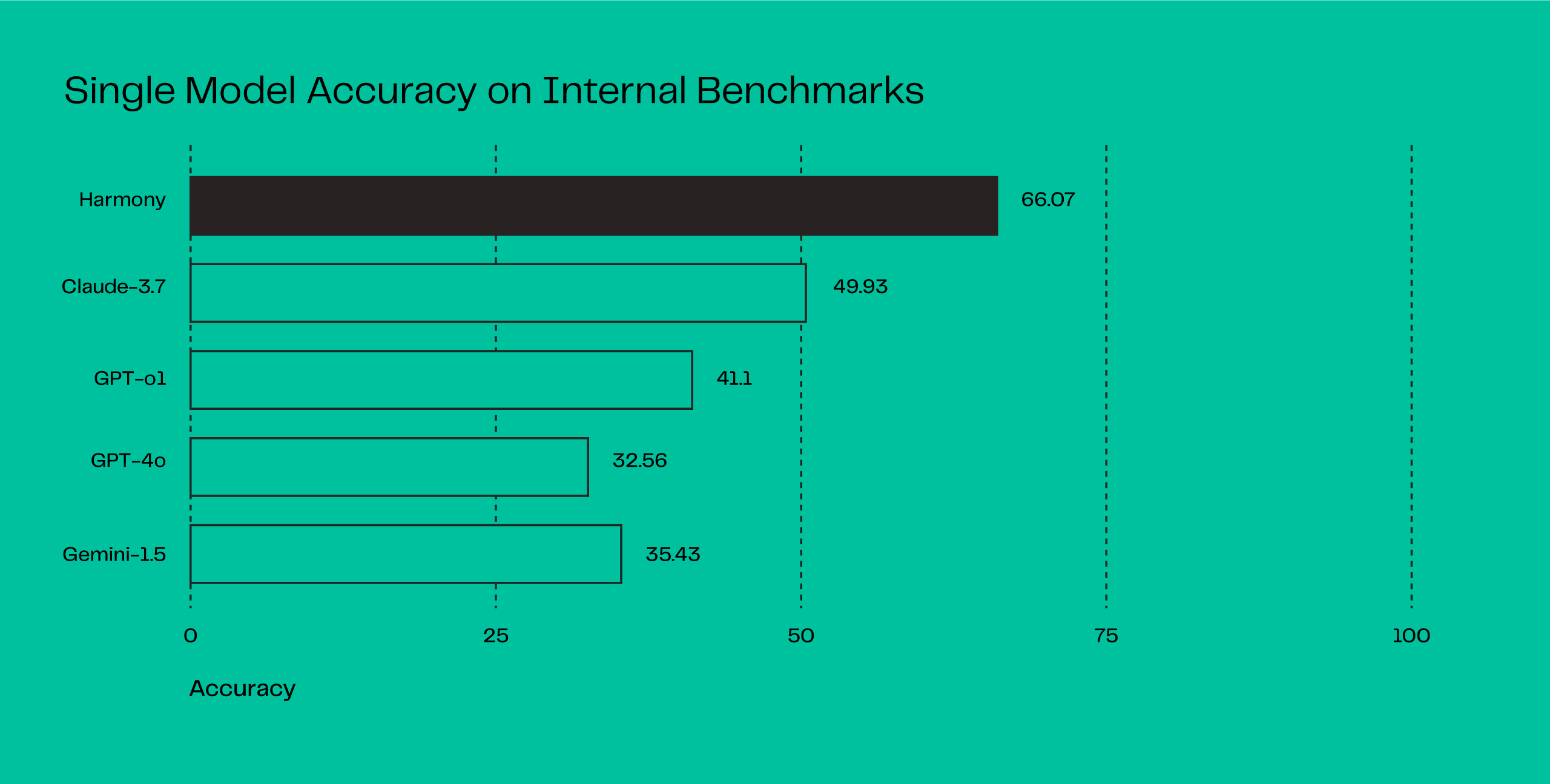
We found that fine-tuned, domain-specialised SLMs can match or even outperform leading general-purpose LLMs, despite being more than 20× smaller in size. As a result, our Harmony models deliver high precision and consistency without the computational overhead of broad, general-purpose reasoning, dramatically improving inference speed and reducing costs, which is a key enabler to resolving software updates at scale.
An additional advantage is that SLMs can be quickly retrained on new codebase versions, allowing them to learn and adapt to new code patterns and large-scale code migrations, common in device development. Equally, they can be trained on existing codebases, before the update, to take into consideration device-specific constraints that often are fogotten years into the software update cycle and lead to hard-to-find bugs.
Combined with the rapid progress of open-source SLM foundations, this adaptability makes SLMs the ideal foundation for Harmony. It also enables operating them in isolated enterprise cloud environments and regularly fine-tuning for the specific software update being performed.
Beyond Single Models
While a single fine-tuned model can already deliver strong performance, developers can solve the same merge conflict in multiple valid ways. To mirror this workflow, we explored how ensembles of small, specialised models perform when tasked with proposing multiple candidate solutions.
To this end, we evaluated the top-3 accuracy (i.e., the likelihood that a correct resolution appears among the top three outputs), using a mixture of Harmony models built on different backbones (e.g., Llama-3.1-8B, Qwen3-4B) and trained on distinct subsets of AOSP-derived data.
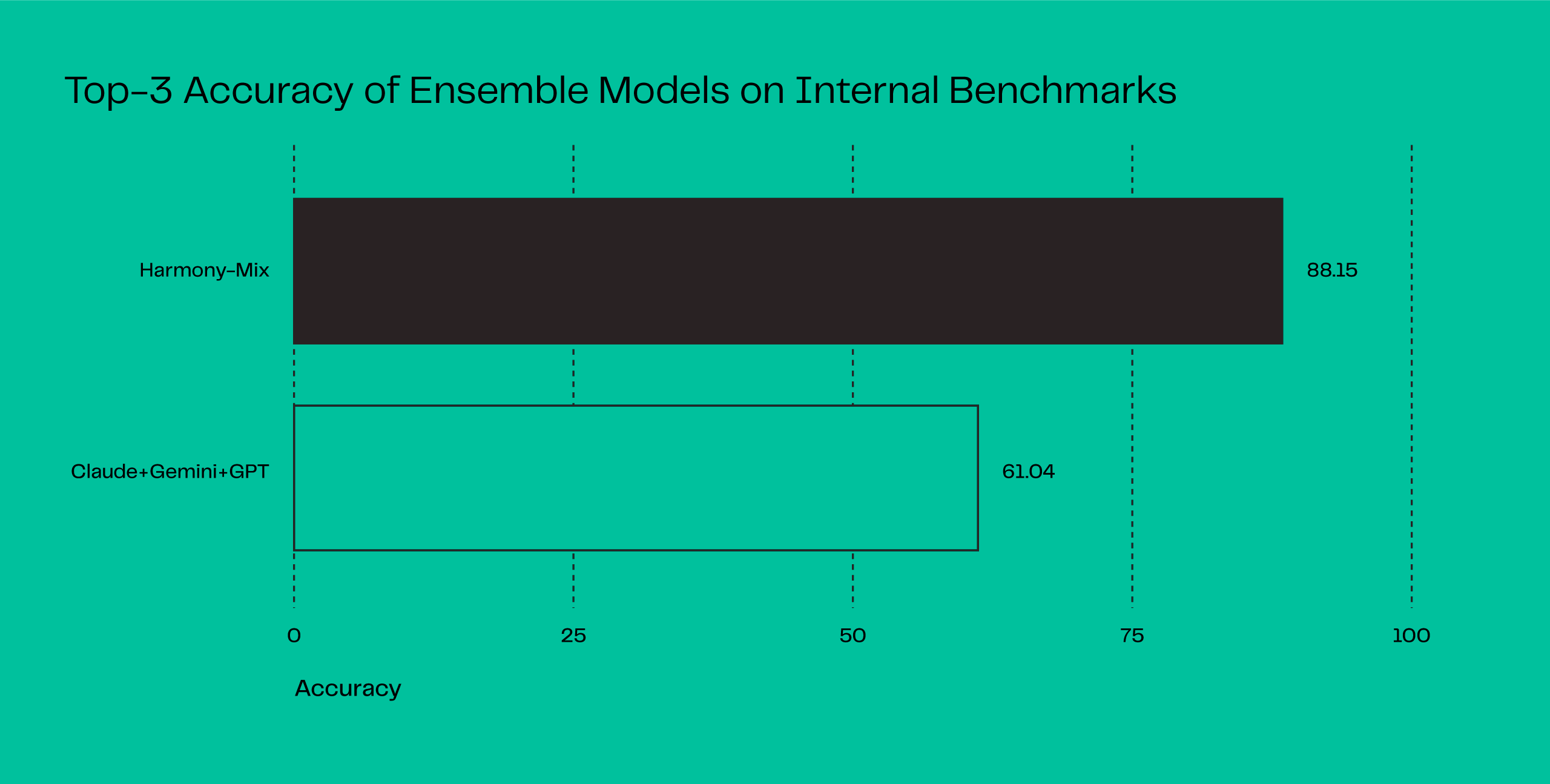
Our ensemble of Harmony models achieved 27.11 accuracy improvement over the ensemble of general-purpose LLMs (Claude + Gemini + GPT).
This result highlights another key advantage of SLMs. Because SLMs are lightweight and cost-efficient, we can afford to train and deploy multiple specialised variants, each capturing slightly different coding patterns or merge heuristics, and then combine their strengths through ensembling.
Agentic Approach to Merge Conflict Resolution
Automated conflict resolution is not a single-step problem; it involves a sequence of interdependent tasks, each posing distinct challenges. For example, resolving a single conflict block may involve analysing just a few files, while verifying the correctness of the final resolution often requires compiling and testing the entire codebase.
Rather than relying on a single monolithic model to handle this entire pipeline, we believe the future of intelligent code automation lies in coordination among many specialised SLMs, each as an expert in a focused part of the workflow.
To this end, we developed the Harmony Orchestrator, an agentic model equipped with robust tools that extend its capabilities in context retrieval, structured reasoning, and validation of proposed resolutions.
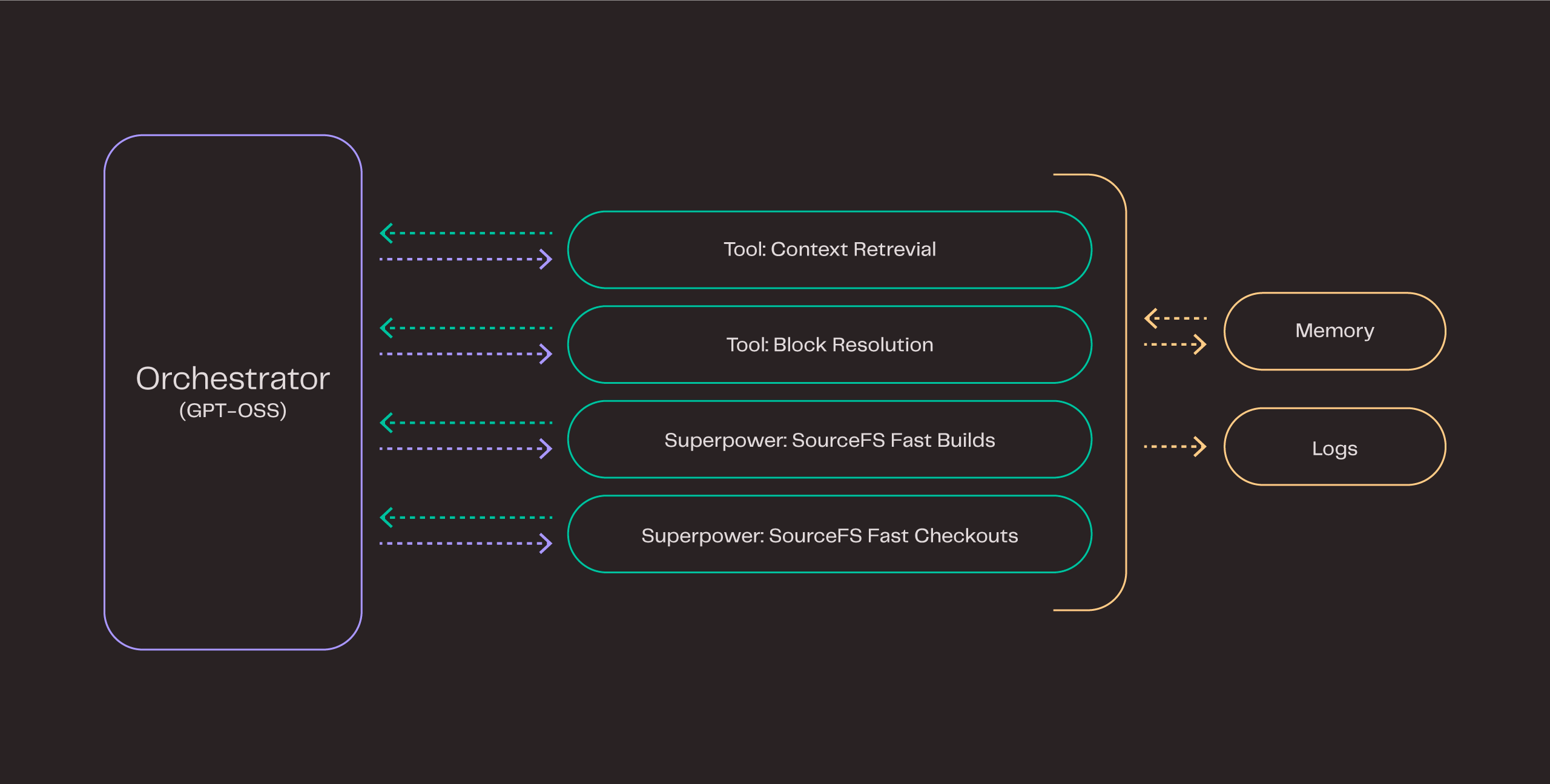
As part of our research into developing the Harmony Orchestrator, we focused on four key aspects that make agentic coordination both efficient and reliable:
- High-quality specialised tools. An agentic system is only as effective as the tools it employs. By integrating with our SourceFS fast checkouts and build superpowers we accelerated the validation cycle 10×. In addition, we are actively developing new superpowers and integrating more of the specialised tooling found in device codebases - all already proving as great optimisation in the next Harmony models.
- Efficient planning and tool-calling. Orchestrator is optimised for high-level reasoning and dynamic task decomposition. Built on top of GPT-OSS, an LLM designed for agentic workflows, it intelligently decides when and how to invoke auxiliary tools. Some tools (e.g, context retrieval or code validation) can be computationally expensive, so the Orchestrator is optimised to balance accuracy and resource efficiency, ensuring high-quality results at minimal cost.
- Validating intermediate results. We use an LLM-as-a-judge validator to verify intermediate results at various stages of the workflow. This approach allows the system to detect and correct potential issues early, reducing error propagation. Flagged cases can be automatically re-run with a higher reasoning budget or escalated for human review.
- Explainability. We put a lot of effort into explainable reasoning. We want to present the human reviewer with structured reasoning explanations, to support the merge approval process. We found that presenting clear, interpretable justifications for each proposed resolution substantially reduces the time developers spend reviewing and approving merges.
Next Steps
We are rapidly productising the next Harmony models and expanding their capabilities and accuracy even further. Early results are outstanding, and we are making strong progress with leading partners toward wider availability.
Our results also reinforce a growing consensus in the research community: smaller, specialised models, when trained on focused, high-quality data, and paired with state of the art tools, can outperform much larger general-purpose models in targeted applications.
For us, this translates to higher accuracy, lower latency, and dramatically reduced costs - which we think is the key to unlocking long-term software updates for all devices.